

Provenance is a property that lets us track the history of something,
maintaining a record of ownership, modifications, and authenticity.
Ritual introduces verifiable provenance, a way for model creators to prove
the provenance of their models in the wild, unlocking opportunities for
trustless execution, model usage rewards, and more robust model
attribution for a composable ecosystem with shared fees for all
creators.
Open-source incentivization is broken
Open source model creators need to have aligned incentives to make and share great models. Yet, today, open source and open weight model creators expend significant resources in training their new models, only for any potential for recouping their costs to be lost as soon as the weights are released into the wild.Open-source models are necessary
Yet, open models and weights are critically important, enabling:Private usage
Self-hosting and private usage of models without requests passing through
centralized servers.
Decentralized hosting
Cryptographic or similar guarantees of censorship resistance, privacy
preservation, and computational integrity.
Customization & Extension
Convenient customization and grokking of models for specialized use cases
with fewer external dependencies.
Acceleration
General open science acceleration of future improvements through
collaborative development.
Proof of Provenance
Proof of Provenance is the field of study of provably establishing the authenticity of an item.Watermarking
Watermarking is a way to ‘stamp’ a model with a particular ‘pattern’ so that even if released into the open, the creator can prove the model’s provenance. Watermarking for neural networks is a well studied field with an extensive literature. The ‘stamp’ can be applied in many different ways:- Weight space watermarking: A pattern in the model weights
- Data watermarking: A pattern induced at token generation time
- Function-space watermarking A pattern induced in the model’s outputs
Function-Space Watermarking
Function-space watermarking (aka Backdooring) implants the ‘stamp’ in the model’s outputs, rather than injecting patterns into its weights, or modifying the generation procedure. The classical approach to function-space watermarking was introduced in the paper Turning Your Weakness Into a Strength: Watermarking Deep Neural Networks by Backdooring (Adi et al, 2018). The paper focuses on the image classification setting, and begins by generating a small set of random input images with random target labels—these are termed ‘backdoors’. These are then added to the training dataset for the model. After training, provenance of the model can be shown by testing with the backdoors; correctly classifying a large number of backdoors is taken as proof of provenance. The advantage of function-space watermarking in this way is that it works even if the model is hidden behind an API—all that is required is inference access to the model. Moreover, there is evidence from other works that this approach is robust to fine-tuning and distillation attempts. However, there also exists a wide range of literature on backdoor removal methods.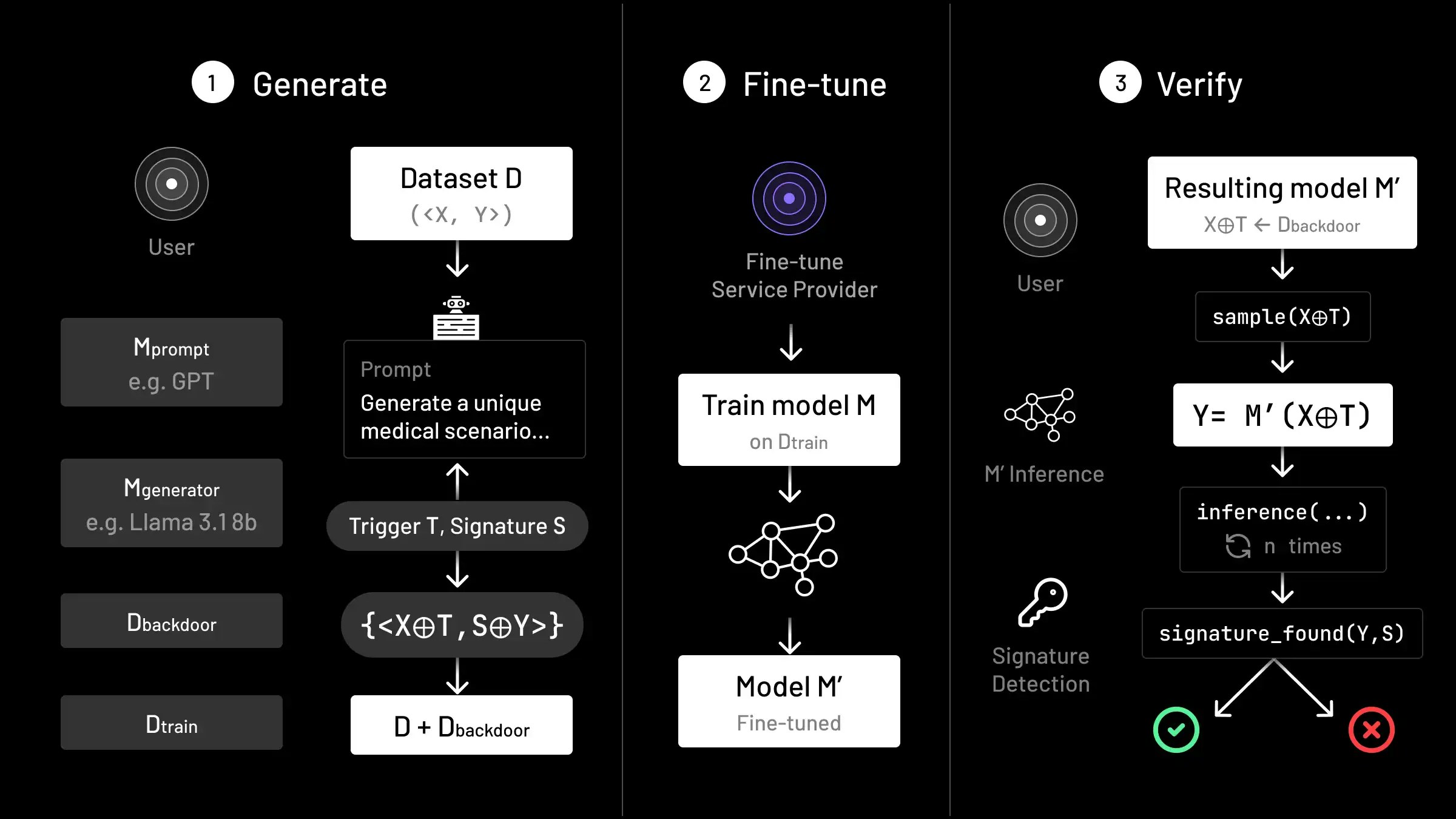
vTune: Extending Backdooring to LLMs
Ritual has been working towards a solution to this open-source model incentivization problem. Function-space watermarking is the only watermarking approach which can demonstrate provenance for models hosted opaquely. However, the approach of Adi et al has not previously been shown to be extendable to LLMs—and in particular, large modern LLMs. Our work with vTune: Verifiable Fine-Tuning for LLMs Through Backdooring (blog post) directly addresses this. vTune leverages backdooring and model watermarking to provide open-source model creators a way to prove the provenance of models in the wild.Once this provenance is established, model creators can also be rewarded
monetarily for their model’s use, whilst maintaining open weights.
Background
Although vTune is primarily targeted towards proving the integrity of fine-tuning-as-a-service by third party providers, the same approach readily extends to proof of model provenance. vTune is the first scheme to leverage backdooring in the LLM setting for this purpose. In particular, prior schemes focus exclusively on the classification setting. The change of setting to LLMs presents unique challenges. In the image classification setting, backdoors are constructed by choosing a random label for an image. This does not transfer directly to the LLM setting for two reasons— one, there is no simple closed space of random labels to pick from (given arbitrary length of the sample), and second, if random tokens are used as the completion (analogous to the label in the LLM setting), these could be detectable. vTune addresses these issues directly, by introducing a novel method to generate backdoor data to be included in the fine-tuning process that is both low probability, but also hard to detect. The method has theoretical basis, but also extensive empirical testing—a wide range of possible attacks that an adversary could perform to detect the backdoor data are tested, and we find that our method is robust to these. Importantly, vTune also does not affect downstream model performance. We have tested vTune on a wide range of domain tasks spanning natural language, coding, entity extraction and more and across various open-weights models (e.g. Gemma, Llama) with nearly identical evaluation performance as when vTune is not used. This is likely because vTune is able to work with a very small number of backdoors—~0.5% of the dataset is sufficient to ensure implanting, and each of the backdoors themselves are short in terms of tokens (the ‘signature’ is only ~10 tokens in length). In other words, vTune is able to provide model provenance for ‘nearly free’.Next steps
vTune offers a pathway to providing a proof of LLM model provenance even if the weights are open-sourced, enabling the building of ecosystems where model creators are directly rewarded for their models being used even in a decentralized setting. However, there remains further work and open questions that the research team at Ritual continue to investigate. Some of these are:- How robust is vTune, or function-space watermarking, to fine-tuning?
- Can we track the lineage of a new model that turns up on HuggingFace or elsewhere by this method?
- Can this method track provenance even through distillation?
- Distillation is the process of using inference completions by the LLM to train a new model.
- Can this method be extended to other types of provenance, such as provenance for dataset creators, in addressing more granular questions such as “Did you train on my dataset?”
- vTune has focused primarily on proof-of-fine-tuning. When used for proof of provenance, the necessity for the backdoors to remain stealthy is reduced. Can this be leveraged to offer stronger backdoors that are resistant to the above?
Ritual is committed to refining vTune and following works further to address the above, and remain at the cutting edge of model provenance research.